[데이터베이스] 관계 대수 (Relational Algebra)
operator 정리
- The usual set operations : $\cup, \cap, -$
- Operations that remove parts of a relation : $\sigma, \pi$
- Operations that combine the tuples of two relations : $\times, \bowtie, \bowtie_\theta$
- Operations called "renaming" : $\rho$
1. Projection($\pi$)
Movie
| title | year | length | inColor | studioName | producerCNo |
| star Wars | 1997 | 124 | true | Fox | 12345 |
| Might Ducks | 1991 | 104 | true | Disney | 67890 |
| Wayne’s World | 1992 | 95 | true | Paramount | 99999 |
projection은 투사, 사영 등의 의미를 갖는 것으로 알고있습니다.
이해는 잘 안되지만, 데이터베이스에서는 "추출"의 의미로 쓰인다고 합니다.
위의 테이블과 같이 Movie테이블이 있다고 생각하면 Movie테이블에서 title, year, length를 추출한 $\pi_{title, year, length}(Movie)$는 다음과 같습니다.
$\pi_{title, year, length}(Movie)$
| title | year | length |
| star Wars | 1997 | 124 |
| Might Ducks | 1991 | 104 |
| Wayne’s World | 1992 | 95 |
2. Selection($\sigma$)
Movie
| title | year | length |
| star Wars | 1997 | 124 |
| Might Ducks | 1991 | 104 |
| Wayne’s World | 1992 | 95 |
Selection연산은 프로그래밍 언어에서 if문과 유사합니다.
$\sigma_c$ 로 표기하며, $c$에는 조건식이 입력됩니다.
예를 들어 $length$값이 100보다 큰 것이 조건식($\sigma_{length\ge100}$)으로 입력되면 조건에 해당하는 튜플만 선택됩니다.
$\sigma_{length \ge 100}$
| title | year | length | inColor | studioName | producerCNo |
| star Wars | 1997 | 124 | true | Fox | 12345 |
| Might Ducks | 1991 | 104 | true | Disney | 67890 |
length가 100 이상인 튜플 선택
$\sigma_{length \ge 100 \wedge studioName = 'Fox'}$
| title | year | length | inColor | studioName | producerCNo |
| star Wars | 1997 | 124 | true | Fox | 12345 |
length가 100 이상이며, StudioName이 Fox인 튜플 선택
Projection과 Selection을 정리해보면,
Projection은 원하는 "열"을 추출할 수 있습니다.
Selection은 원하는 "행"을 추출할 수 있습니다.
따라서 두 연산을 조합해서 사용하면 원하는 원하는 tuple에서 원하는 column을 뽑아낼 수 있습니다.
3. Cartesian Product ($\times$)

위와 같이 $R, S$ set이 있다고 생각해보겠습니다.
R의 두 튜플을 $(r_1, r_2)$라고 하고, S의 세 튜플을 $(s_1, s_2, s_3)$라고 하면,
$R$과 $S$의 카티시안 곱은 다음과 같습니다.
$$R \times S = {(r_1, s_1), (r_1, s_2), (r_1, s_3), (r_2, s_1), (r_2, s_2), (r_2, s_3)}$$
따라서 $R \times S$는 다음과 같이 표현됩니다.

카티시안 곱은 데이터가 너무 많이 늘어나는 이유로, 실제로는 자주 사용하지 않는다고 합니다.
4. Natural Joins ($bowtie$)
$R \bowtie S$는 column이름이 같은 부분을 Join하는 방식으로, 동일한 타입과 이름을 가진 컬럼을 join 조건으로 이용하는 join을 간단히 표현하는 방법입니다.
공통 부분이 없다면, 카티시안 곱과 동일한 결과를 얻게 됩니다.
$R$과 $S$라는 두 set이 주어졌을 때, $R\bowtie S$ 연산은 다음과 같이 진행됩니다.
Natural join 예제 1.
1. 공통된 column을 찾습니다.

2. 공통된 column에서 tuple별로 비교하면서 동일한 부분을 찾습니다.
$\quad$ 2-1)

$R$의 column B의 첫 번째 튜플(2)과 $S$의 1, 2, 3 번째 튜플을 비교해보면 $S$의 첫 번째 튜플만 2로 동일한 것을 볼 수 있습니다.
따라서 다음과 같이 $R\bowtie S$에 추가합니다.
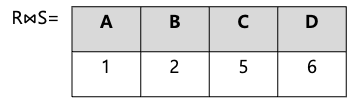
$\quad$ 2-2)

다시, $R$의 column B의 두 번째 튜플(4)와 $S$의 1, 2, 3 번째 튜플을 비교해보면 $S$의 두 번째 튜플만 4로 동일한 것을 볼 수 있습니다.
따라서 완성된 $R\bowtie S$은 다음과 같습니다.

Natural join 예제 2.

다음과 같이 $U$와 $R$이 주어졌을 때, $U \bowtie R$을 구하는 과정은 다음과 같습니다.
1. 공통된 Column을 찾습니다.

2. 공통된 column에서 tuple별로 비교하면서 동일한 부분을 찾습니다.
$\quad$ 2-1)

두 개의 튜플과 동일하기 때문에 $U \bowtie R$은 다음과 같습니다.

$\quad$ 2-2)

한 개의 튜플과 동일하기 때문에 $U \bowtie R$은 다음과 같습니다.

$\quad$ 2-2)

동일한 방식으로 진행하여 다음과 같은 최종 $U \bowtie R$을 얻을 수 있습니다.

5. Theta-Joins ($\bowtie_\theta$)
Theta-joins는 $\theta$로 표현되는 "조건"이 붙는 연산이며 다음과 같은 성질을 갖습니다.
$$R \bowtie_\theta S = \sigma_\theta (R\times S)$$
즉, $R \bowtie_\theta S $는 $R$과 $S$를 카티시안 곱으로 표현한 다음, Conditional Selection을 하는 것과 동일합니다.

위와 같이 $U, V$가 있을 때,
$U\bowtie_{A<D}V$ 는 $U\timesV$에서 $A<D$를 만족하는 튜플만 남겨놓은 것과 같습니다.
$U\times V$를 구해보면 다음과 같습니다.

여기에서 $A<D$를 만족하는 튜플만 남기면
$U\bowtie_{A<D}V$를 구할 수 있습니다.

'[컴퓨터공학] > [데이터베이스]' 카테고리의 다른 글
| [데이터베이스] SQL 집합 연산 (0) | 2022.06.13 |
|---|---|
| [데이터베이스] Null Value (0) | 2022.06.12 |
| [데이터베이스] Pattern match, Posix Regular Expression (0) | 2022.06.12 |
| [데이터베이스] Relational Algebra 예제 (0) | 2022.03.30 |
| [데이터베이스] 데이터베이스, DBMS (0) | 2022.03.09 |